Scaling Vortexa Oil & Gas Datasets with AWS Data Exchange
On the benefits of AWS Data Exchange for sharing large data sets
Thursday, 16 January, 2020
Scaling Vortexa Oil & Gas Datasets with AWS Data Exchange
On the benefits of AWS Data Exchange for sharing large data sets
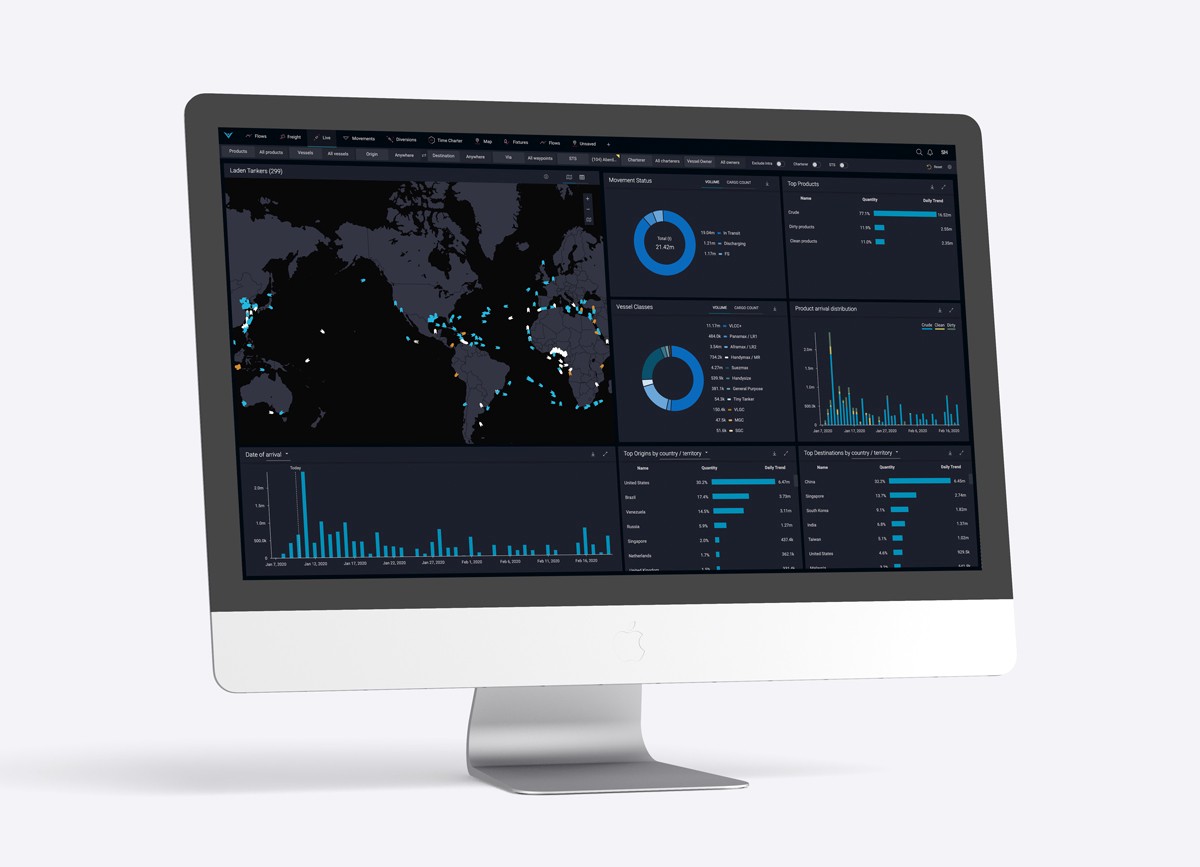
Vortexa’s analytics platform provides a beautiful and convenient way to explore the vast amounts of oil & gas data Vortexa generates in next to real-time. At the same time, a few of our customers prefer to feed our entire raw datasets into their pipelines for offline processing. One use case for importing the whole dataset is the need to run in-house advanced market analysis models to identify potential trading opportunities in the energy markets. As our dataset changes, incorporating new predictions and revising the previous ones as the latest information comes in, those customers need an easy way to regularly and automatically re-acquire and re-import Vortexa data. Fundamentally, there were three primary ways to do so until recently:
- Manually export CSVs from the platform.
- Use Vortexa Excel plugin to export the data.
- Get close-and-personal with the Vortexa API.
Each of those approaches has its strong and weak points, both for Vortexa and our customers. For example, manually exporting CSVs would require a human doing so every so often. Any Excel plugin is constrained by the limitations of the add-in model developed by Microsoft for its Excel product. And lastly, using Vortexa API requires a certain learning curve on the customer side, let alone using a fine tool designed for finding the needle in the haystack to solve the problem of exporting many terabytes of Vortexa’s data is like hammering nails with a microscope.
Since then, Vortexa introduced two new ways to access its data: using Vortexa’s Python SDK and using AWS Data Exchange.
The Python SDK significantly reduces the learning curve. It can be used to export Vortexa’s raw data. Yet, its strength is in enabling industry analysts and data scientists to explore and transform data and run quick experiments dynamically. It deserves a separate post, so watch this space. Here, we will focus on AWS Data Exchange. Let’s first take a sidestep to understand why.
In November 2019, Amazon launched the AWS Data Exchange. It is a new service that would not necessarily have ended up on the radar of traders, analysts and data scientists. No doubt it will take some time to gain momentum. And yet, its significance should not be underestimated. To understand why let’s have a look at where AWS Data Exchange fits.
Amazon has worked hard to become a leading online retailer. Even two years ago, in 2017, its second-largest revenue stream was from third-party sellers, offering their products on the Amazon retail platform. Every time you buy a product which is not sold by Amazon itself, you are becoming a buyer on that market.
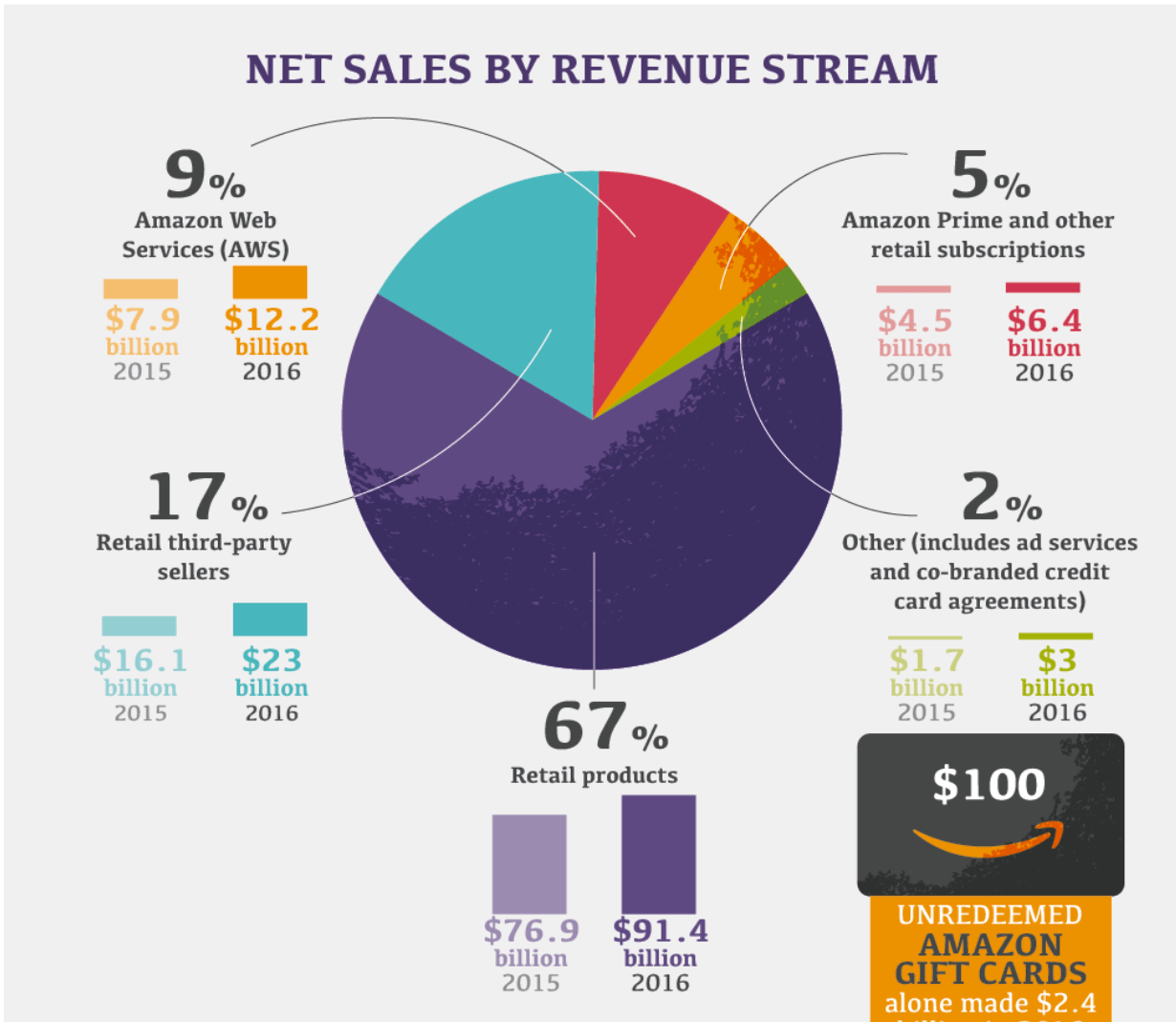
A lesser-known fact is that in 2019 over 50% of Amazon sales come from third-party sellers. Naturally, Amazon is best known for its retail services. Still, it is not difficult to realise that very similar rules and principles of Marketplace apply to the new type of goods of the 21st century – data. While the ability to purchase data has existed for some time, Amazon has the scale and the dedication to move the needle. For example, AWS Marketplace, a curated digital catalogue that includes AWS Data Exchange, is available in 20 AWS regions, already has over 260,000 active customers and over 1,000,000 current subscriptions.
AWS Data Exchange has been born as a centralised easy-to-use way for the sellers to offer their datasets up for sale and the buyers to easily browse available datasets and use the same method to access any datasets. Simplistically speaking, it is a way to publish one or more datasets with one or more revisions of data in it in a way that provides multiple benefits to the sellers and buyers:
- Sellers: streamlined billing, additional marketing opportunities, access to a broader customer base that otherwise may have been difficult to reach, a scalable way to programmatically export terabytes of data once and have it downloaded multiple times without any extra costs or infrastructure overheads.
- Buyers: a unified interface to access the data, commitment from Amazon to develop and extend that interface, high data availability and deterministic latency, likely proximity of data to the computing environment in case a customer is using AWS for their modelling, as well as a trustworthy and familiar billing partner, Amazon.
Both benefits can reduce the seller costs and improve buyer user experience immensely compared to a home-grown bespoke system dedicated to sharing the raw data.
Here is how one of Vortexa’s products looks like on AWS Marketplace:
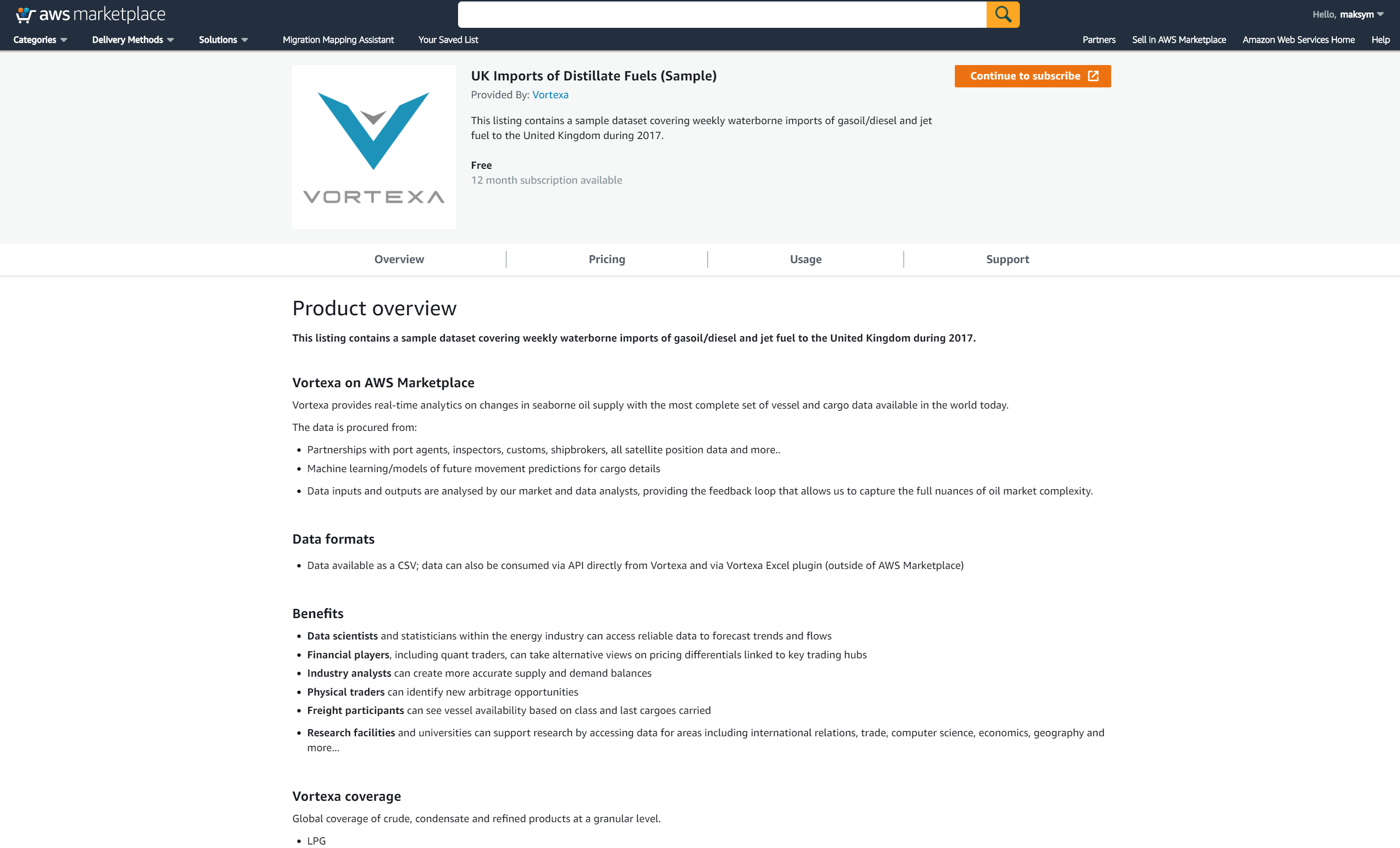
There are a few useful articles that describe how to access the data programmatically. Fundamentally, accessing the data is as simple as (from an article on AWS Big Data Blog):
- Configuring your prerequisites: an S3 bucket for your data and IAM permissions for using AWS Data Exchange.
- Subscribing to a new Vortexa data product in AWS Data Exchange.
- Setting up automation using Amazon CloudWatch events to retrieve new revisions of subscribed data products in AWS Data Exchange automatically.
Once that is done, the data in CSV format, in Vortexa’s case, will automatically appear and get updated every time Vortexa publishes a new revision. You can then import and process it any way you like! The newer versions of Boto, a popular AWS SDK for Python, support AWS Data Exchange as well.
So in conclusion, AWS Data Exchange provides the buyers with an easy-to-use unified way to access multiple data sources, while creating an effective and efficient way to distribute data at scale for the sellers. It is a true win-win!
Author: Maksym Schipka, CTO at Vortexa
For more practical tips on Data Science and Tech – follow the VorTECHsa team on Medium




