Vortexa’s Python SDK for a Programming Novice
Python for beginners
From Data Analyst to Python Developer
I’ve not taken the usual route in becoming a Python developer. I loved every part of my degree; BA Geography at Northumbria, however, this isn’t a degree often associated with writing code. I had opted to take a placement year and the skills in the GIS modules at university set me up well for an internship at Vortexa as a geospatial data analyst. My first role was mapping out Vortexa‘s internal view of the world. During my internship, I ended up learning SQL as I found it an essential tool for data analysis.
When learning SQL I found that there were 3 components required;
- Resources for learning the basics – I used w3schools as my main resource.
- Mentors on my team who I could turn to when I was having an issue – Vortexa’s data scientists and engineers were more than willing to take time out of their day to help me build a complex query.
- Practice. The more queries I did the easier it became.
After completing my internship I returned to University to finish my degree. 11 months later having finished my degree, I rejoined Vortexa and expressed an interest in learning how to code.
My colleagues suggested Python as a good beginner language. I had always admired the skills of my mentors who helped me learn SQL and felt I was in the perfect setting to learn.
Since rejoining I’ve found that with a bit of time and effort, anyone can become adept with Python and unlock a level of analysis that can answer questions previously viewed as too complex to even attempt!
I approached learning Python the same way as SQL, however rather than using a free resource, I enrolled in a course on Udemy. The course shows you the basics of Python; how to it set up on your machine and how to run Jupyter notebooks. Jupyter notebooks are a great resource when learning Python as they allow you to run blocks of code and see the results at each stage; you don’t have to run a whole script every time you want to see how your new code has changed the output.
Initially, I would arrive an hour earlier at work to learn Python, and after one month of learning on my own, I became confident enough to start picking up Python tasks. This is when my learning started to accelerate as not only was I doing the course for an hour before work, I was getting to practice during the day, tackling real-world problems. Vortexa had grown significantly during the time I was back at university. Along with the familiar faces and previous mentors, there were even more people willing to take time out of their day to undertake pair programming with me.

In the office raising money for Movember with two of my mentors Tino von Stegmann (left) and Kit Burgess (middle)
Finally, when I started learning Python I found that many of the libraries and modules you imported had great examples that once understood, you could tweak slightly to your use case and they worked perfectly. Should any tweaks you make not work you can also turn to Stack Overflow. For those who don’t know Stack Overflow, it is a website where people post their coding issues and members of the community help fix their problems.
Now that I’ve told my story of learning how to code let’s work together to answer one of the hottest topics in the oil market using the Vortexa Python SDK.
Finding Answers to Hot Topics in the Oil Market
“We built the SDK to provide fast, interactive, programmatic exploration of our data. The tool lets Data Scientists, Analysts and Developers efficiently explore the world’s waterborne oil movements, and to build custom models & reports with minimum setup cost.” – Kit Burgess, Senior Data Scientist, Vortexa
Using Python, we will pull Vortexa’s data into a Pandas DataFrame using the SDK. (Pandas is an open-source data analysis and manipulation library for Python). We will also go through how to export the final DataFrame as a CSV (which you can share with colleagues), or open in excel, ready to be analysed.
We will look at how to tweak the example code to get floating storage data for crude oil and condensates currently floating offshore China – a hot topic in the trading world right now. Floating storage is being watched closely in the oil markets as China is a huge importer of crude and any indication of a supply surplus or deficit can have a major impact on global oil prices.
Along the way, I’ll share a couple of tips and tricks which I have learned over the past year. You can also access the Jupyter Notebook used throughout to follow along, here.
Getting Started
In the SDK documentation, there is a setup FAQ section, found here. It covers everything you need to know to get started using the SDK on your machine; including where to request a demo.
Importing Modules and Libraries
At the start of the notebook, we have to import the libraries and modules which we are going to be using. In this notebook, we use three of the Vortexa SDK’s endpoints, the DateTime library, Pandas and Matplotlib. To use them in the notebook, we have to import them like this:
from vortexasdk import Products, CargoTimeSeries, Geographies
from datetime import datetime
import pandas as pd
import matplotlib.pyplot as plt
Products Endpoint Tutorial
First I’m going to show you how to get the Vortexa ID for a product you are interested in studying from the products endpoint. Whilst there are many ways of doing this, I will show you just one example that I believed was the best option. In the documentation for the products endpoint, we can see an example line of code which shows us how to look in for different products in a list.
df = Products().search(term=['diesel', 'fuel oil', 'grane']).to_df()
Let’s run that cell in the Jupyter Notebook When you are running the first cell, the side will change from `In [ ]` to `In [*]`. When the cell has finished running it will change to `In [1]`.
If you type `df.head` in a cell and run it, you can see the first few results for the example query.
What we are doing is calling the head() function which is used to get the first n rows of a DataFrame. The number of rows you return is defined by the number within the brackets, by default, this number is 5.
Without knowing much about Python you can see that there are three terms in square brackets that are used to describe products in the oil world, and the query returns every product ID in which the name contains one of the values in the list. To search for crude/condensates product ID we can delete those three terms and put in ‘crude’ instead:
crude_search_df = Products().search(term=['crude']).to_df()
The output of that query currently returns 18 products with the term ‘crude’ in their name. As we want only the information contained in one row of the DataFrame where the name column is equal to ‘Crude/Condensates’ we can query the DataFrame:
crude_search_df.query("name=='Crude/Condensates'")
A handy tip is to increase the width of the columns displayed in the Jupyter Notebook is to run this command
pd.set_option('max_colwidth', 75)
Now if we run our query again you can see the full width of the column and the whole ID.
In the notebook, I have also shown how to query the geographies endpoint. However, as it’s similar to the products endpoint, there’s not much point going into detail. Instead, I’ll demonstrate how to change the CargoTimeSeries endpoint example and look at our hot topic – crude floating storage in Chinese waters.
CargoTimeSeries Endpoint Tutorial
First, let’s look at the example in the documentation:
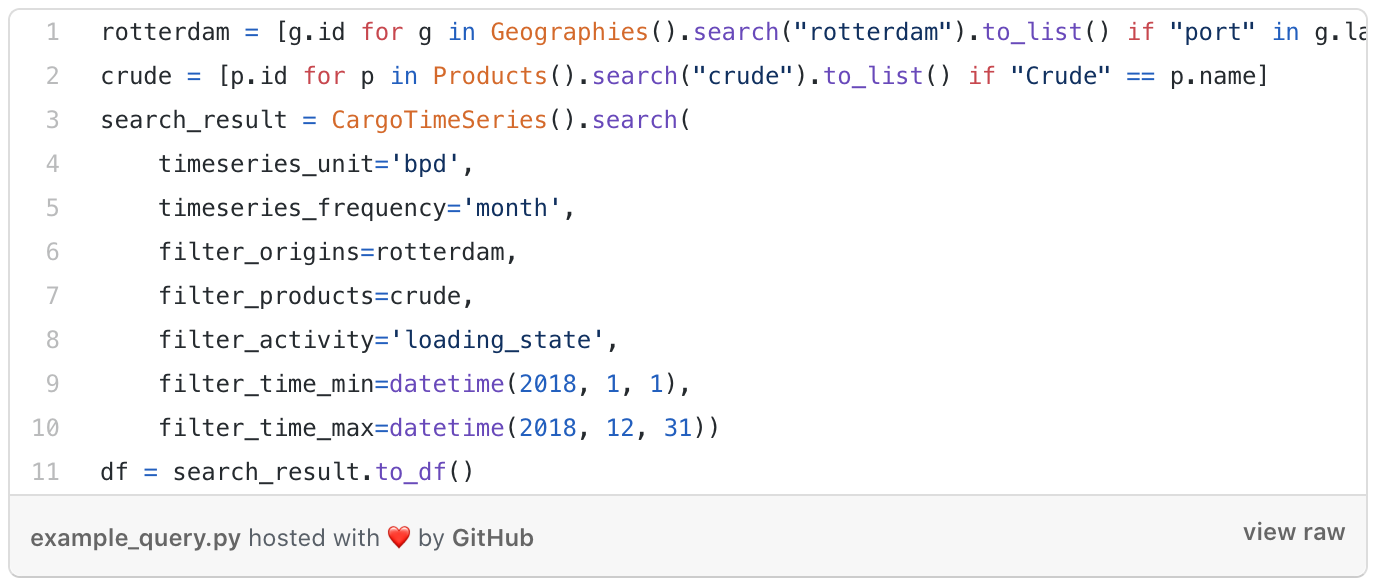 CargoTimeSeries endpoint example from the SDK documentation
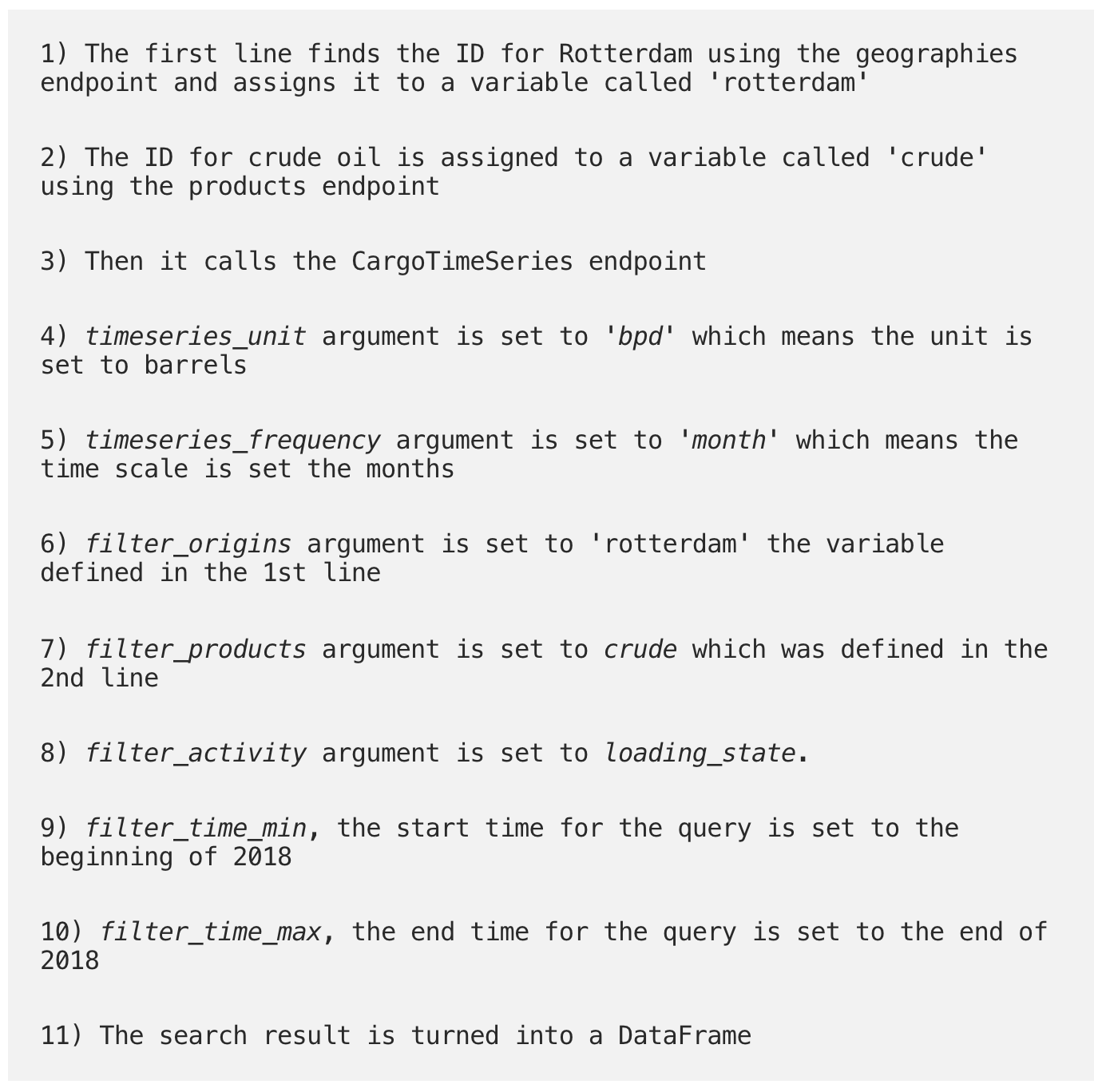
CargoTimeSeries endpoint example from the SDK documentationTogether let’s break this down line by line to understand what is going on.
Now let’s see the changes made to the example query:
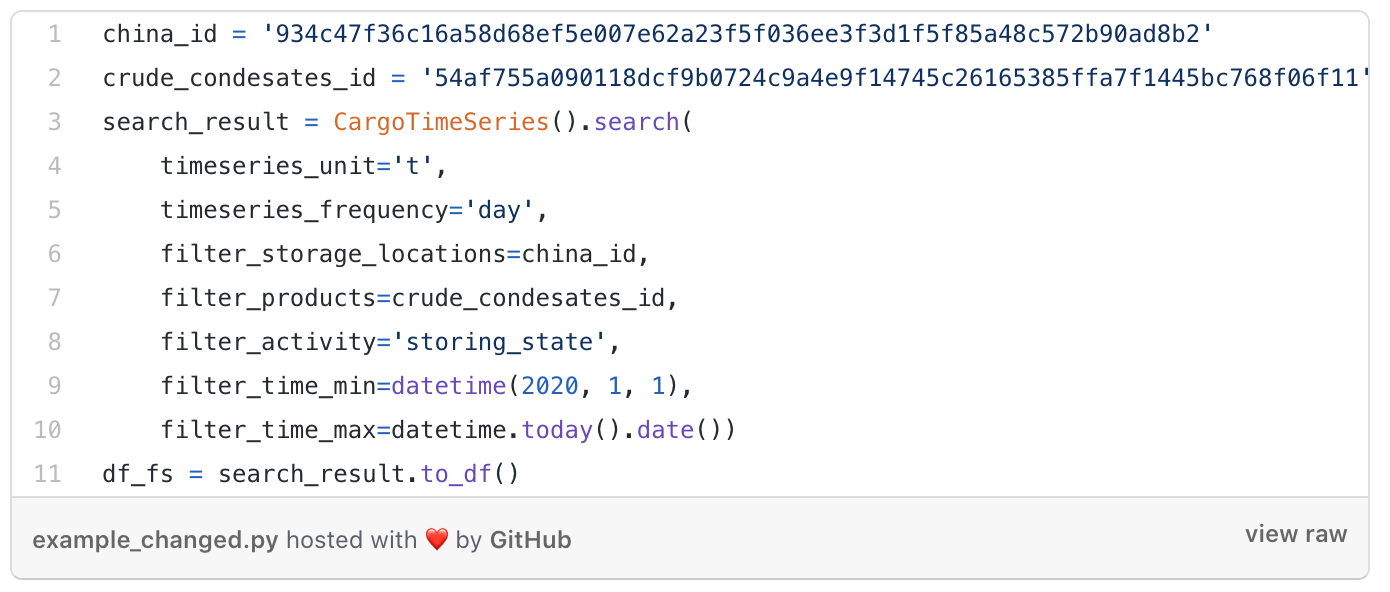 CargoTimeSeries endpoint example query changed to return floating storage in China
CargoTimeSeries endpoint example query changed to return floating storage in ChinaAgain let’s break down this line by line to understand the changes we’ve made:

Exporting your data as a CSV
If you would like to export the final DataFrame as a CSV, use the following :
df_fs.to_csv('~/Desktop/chinese_floating_storage.csv')
On your desktop, there should now be a file called chinese_floating_storage.csv
Final Thoughts
Today we’ve learned how to take example code from Vortexa’s Python SDK documentation and change it to fit a real-world example. This is a skill you can translate to any Python package. If you would like to look into more examples for the Vortexa SDK you can find all of the documentation here.
I hope after reading this and following along with the Notebook you’ve gained more confidence writing Python code and can see that learning the language is not as daunting as it looks. Python allows the user to be versatile with their data and provides even deeper analysis, as can be seen through the Vortexa Python SDK.
And that’s all there is to it.




