Where’s your (over)head at? Pt II
Getting stuck into Python performance tips.
Getting stuck into Python performance tips
This is the second article of this series, outlining how to think about data processing code in the Python world, and more specifically, how we can improve our code performance while writing legible, maintainable, production-quality code. You can read Part I here.
Background
So, you’ve decided that Python is the right tool for your use-case. Chances are that if you are working with anything larger than a truly tiny dataset, you will probably default to using the Pandas library; and if you are not, you probably should consider it. Let us briefly review what makes Pandas such a popular tool for data processing.
The Pandas library has rapidly evolved into the de-facto data processing library in the Python world. One core reason for this is the DataFrame structure, and the mental framework it provides its users. In most cases, real-world data can be very effectively represented in a tabular format; with rows and columns representing observations and features respectively. The Pandas DataFrame structure is arguably the most efficient and intuitive way to represent and interact with this sort of data, in a computational context.
On top of this, Pandas comes shipped with an incredibly rich ecosystem of tools that make routine operations such as I/O (reading and writing data), transformations, calculations, and even visualisations very, very easy – and in many cases very efficient. Most standard ETL operations boil down to a single method call, or maybe even 2 or 3 methods that can efficiently and legibly be chained together.
This echoes a core feature mentioned in part 1 of this series, about the strength of the wider Python language, namely how it is built to optimise developer speed. However, as with the Python language as a whole, Pandas’ ease of use and variety of tools means that it is very easy for inexperienced users to write code, which works exactly as intended, but in a terribly inefficient way.
We are now going to look at some common data processing patterns, and how to do them as efficiently as possible, using Pandas, whilst aiming to maintain a high degree of legibility in our code.
Iteration
Iterating over some collection of data and executing an arbitrary operation on each element, is the bread and butter of programming. This is no different in Pandas. However, this common use-case is one where less experienced Pandas users often incur some of their biggest performance penalties.
To understand how we can do this fundamental operation in the most efficient way, we will fall back on this brilliant article [1] and accompanying talk [2], by Sofia Heisler. All credit for the tips in the following section goes to Ms. Heisler, so if you find it helpful, please see her original article and talk, and Like, Clap and Share her work.
Ms. Heisler uses the following function as her baseline example.
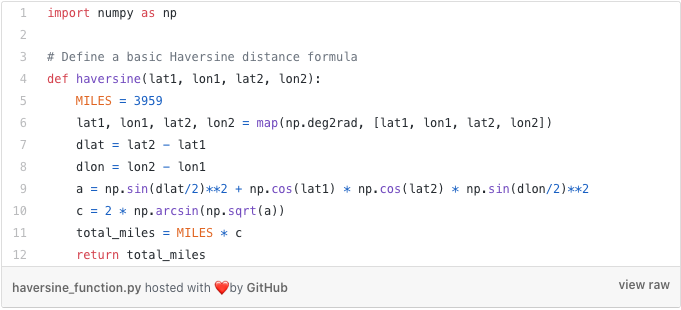
This example is very applicable to us here at Vortexa, as trigonometric functions like the Haversine distance, form the core of several of our important algorithms. The Haversine function is a simple way of calculating the distance between 2 given points on a sphere. At this stage, all you need to take away from the formula above is that there is no magic, just some simple trigonometric transformations, and arithmetic.
In her example, Ms. Heisler has a DataFrame containing approximately 1,600 rows with latitude and longitude coordinates. She then wants to calculate the distance from a given coordinate pair, to the coordinates contained in each row of her DataFrame.
The for-loop
If you are new to Pandas, the default approach you will take here is arguably to use a for-loop.
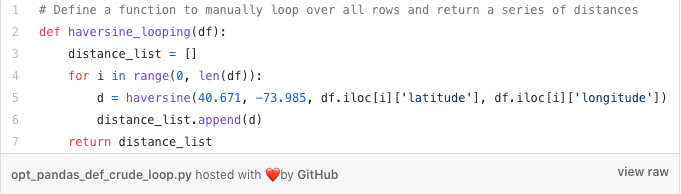
Here we see a very common pattern – we define an empty list (distance_list), create an iteration counter (i) which increments between 0 and the length of our data-set, and use this to access data in each row and pass it to our haversine function. We append the result of each loop to our `distance_list` and return the list when the loop is exhausted. How does this approach perform?

Our simple looping approach takes just over 600ms. That does not sound too bad, however, if we consider that our haversine function just does simple mathematics – which computers are meant to be optimized for – and the fact that we only have 1,600 records, you may start to see that this approach will quickly become sluggish as we encounter larger datasets.
Iterrows
Another very common approach used by less experienced Pandas users, is the `.iterrows()` method.
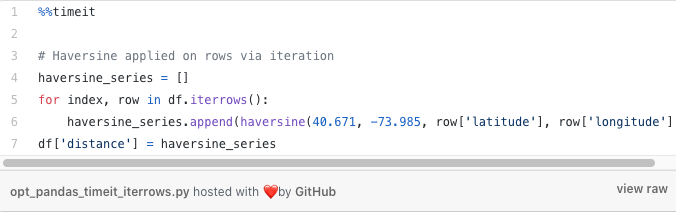
Iterrows essentially behaves like Python’s `enumerate` function. For every row in our DataFrame, it returns the index value and the row’s data (as a Pandas Series object). This means less clutter in our code, as we no longer need to create an iteration counter or access our data using the clunky `df.iloc` notation. So it arguably results in neater code, but what about performance?
That is 4x faster than a basic for-loop! This is a good start, but if you read any number of StackOverflow questions you will quickly see grave words of caution uttered against the use of iterrows. So let’s look at a better alternative.
Apply
This is the approach most commonly found among intermediate Pandas users, and for good reason. The `.apply()` method is really the swiss army knife of Pandas’ calculation tools. It is more efficient than for-loops or iterrows, and there is almost no function that you cannot package into an apply-friendly shape.
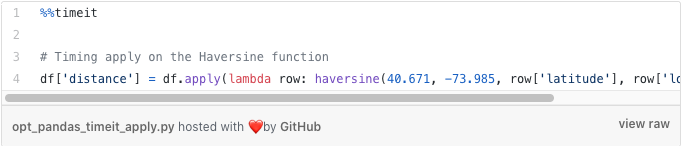
The other advantage we immediately see is how much more succinct an apply call is when compared to loops or iterrows. Our multi-line code snippets from before have been replaced with a simple one-liner. On top of this, we can immediately assign the output of our apply operation to a new column, without first having to store the results elsewhere. Despite the slightly odd ‘lambda’ syntax, we can see that our apply is more legible and succinct than previous attempts and below we can see that it is almost 2x faster than iterrows too.

There is, however, a common misconception that the relative speed of an apply statement is due to it being a vectorized operation. Fortunately, Ms. Heisler provides clear evidence that this is not the case, by using a line-profiler.

Here, we see that every line in our haversine function got called 1631 times, meaning it got called once for every row in the DataFrame. In other words, apply is just a more efficient way of looping. This begs the question, how do we achieve this fabled vectorization?
Vectorization
It turns out, in this example, using a vectorized implementation could not be simpler.

Our haversine function has already been written using tools from the powerful NumPy library, so in order to implement this function in a vectorized manner, we simply need to pass the columns (or Series objects) directly into the function as arguments.

This approach turns out to be almost 60x faster than using apply (and at this point almost 400x faster than our first Python for-loop approach)! Using the line-profiler tool again, we can see the reason why.

Now, each line in our function gets called once in its execution. But it turns out that we can do more.
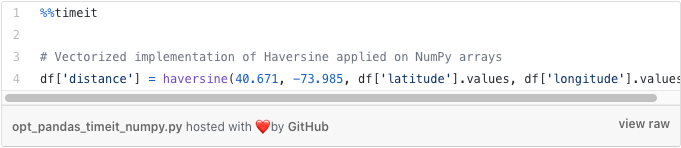

This time, while passing our Series objects as arguments to our haversine function, we simply prepend them with a `.values` call – this gives us a further 4x speed improvement. What is going here?
Calling `.values` on a Pandas Series object returns a NumPy array. There is a lot to unpack and understand when discussing the differences between a NumPy array and Pandas Series, more than we have time for in this article. Two of the core differences to note are that NumPy arrays do not contain a defined index (only an implied integer index), and the mechanisms by which Series and array objects access values in memory also differ. For now, I would suggest using the `.values` approach in cases where your columns contain homogeneous datatypes, and where your calculations consider each row’s values independently.
Maths only?
So far we have seen some fantastic performance tips for doing mathematical calculations, by iterating over a dataframe in different ways. However, as a comprehensive data processing tool, there are many other use cases we may want to consider, when speaking about Pandas performance tips.
For the following examples, we will be using some of Vortexa’s real-world data. In this case, we have loaded a dataframe of 940,000 rows x 15 columns, containing cargo movements data.
Simple Conditionals
Applying conditional logic to our data is a common use-case. Let us take an example where we wish to classify cargo movements depending on their respective country of origin.

This is a case where many intermediate users will resort back to an apply statement. After all, it is very simple to conceptualize this sort of operation in a pure function, and then ‘throw’ it at your DataFrame using apply.

Here we see that a simple apply took 16s. Granted, we cannot compare this to our previous haversine examples, as we are using a much larger dataset, but this is still incredibly slow. However, you may have noticed that our `find_nordics` function only requires one input, yet we are calling the apply method on the entire DataFrame. It turns out that in these cases we can simply call our apply on the Series we wish to use as our input.

Although it does not feel like it should make much difference, the performance improvement here is vast (~100x). So, please use this as a word of caution, not all apply(s) are created equal!
As we have seen before, apply is fundamentally still a looping approach. If we wish to improve the performance of this operation, we can take a page out of the book of high-performance databases. Many relational databases, when asked to execute a conditional statement, do not branch their data down 1 of 2 execution paths, instead they execute both conditionals on each row, and logically combine the results.
In Pandas, we can do the same by making use of the concept of masks. A mask is created by calling a conditional statement on a column (or columns) of a DataFrame. It will return a Series containing True or False for each row, depending on whether or not it met the conditional logic. We can then use this mask to update our values accordingly.
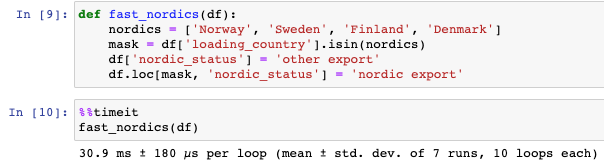
We have again defined a list of countries corresponding to our definition of Nordics. We then created a mask to determine whether each row in the `loading_country` column is in our Nordics subset or not. We then create a new column, setting every row to the default (i.e. `else`) value, and finally use our mask to update only the rows corresponding to nordic exports. The output is the same as before, but achieved almost 5x faster than with a Series apply.
We can achieve similar performance benefits, by using the NumPy `where` statement.

The `where` statement reads almost like a ternary operator in other languages (condition, if true, if false). The performance is virtually identical to our mask approach, so it really boils down to personal preference on legibility as to which approach you choose to take.
Multiple Conditionals
Things often seem to get a little daunting when we move into the territory of more complex, multiple conditionals. Below you will see an example of a pretty odd piece of logic, but it is there for illustrative purposes.
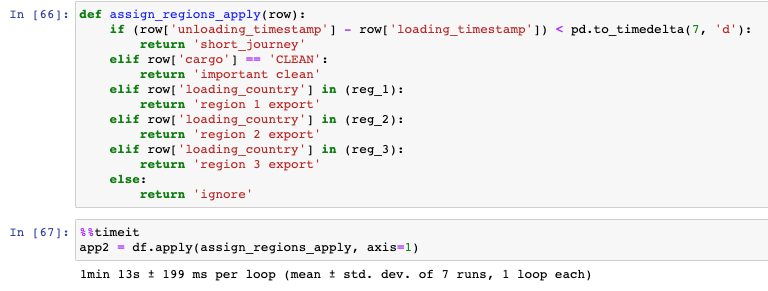
Our multiple conditional function evaluates several values within each row, so we cannot use the more efficient Series apply approach here. As a result, we are left staring blankly at our screens for over a minute, waiting for this apply to complete.
I have seen plenty of users, familiar with mask syntax, falling back on apply statements when it comes to executing multiple conditionals. Part of the reason is that unlike in simple conditionals, in multiple conditionals, order matters. But fear not, it really is not that difficult to gain serious performance improvements here.
Let’s take a look at a mask approach first. To do so, we start by creating multiple masks and assigning each Series to a variable name. These masks are mutually exclusive and correspond 1-to-1 with our if/elif statements above. The key to maintaining the correct logical order of execution, is simply to flip our traditional if/elif/else loop on its head. We start by defining the default value (the else statement), then we work our way up through the `elif` statements (in the exact reverse order), and finally apply the mask corresponding to our `if` statement.

This may seem a tad confusing at first, but looking at the performance results, it is certainly worth understanding and locking this type of pattern down in your toolkit. Again, legibility is a major consideration when writing production-quality code, and using this sort of inverted logic can require a little more thinking on the part of someone reviewing or editing the code at a later date. Fortunately, NumPy provides help in this scenario.
Much like with our simple conditionals, we could use a `.where` statement here.

The performance is similar, however, the nested statement approach is a mess, and will incur more mental overhead for anyone looking at this code, so in my opinion, this should not be used. The NumPy developers, fortunately, provide an even more useful tool in this case. Enter the `.select` statement.

The `select` approach is similar to our Pandas masks approach, in that we start by defining a series of conditional statements inside a list. The key difference here is that the statements are listed in the same order as they would be in a traditional if/elif/else statement. We then define a list of results, corresponding to our conditional statements; it is important that these lists align exactly in terms of size and order. Then we simply pass our conditions and results into the `np.select` statement, listing our default (else) value as the final argument.
Again, our Pandas and NumPy approaches perform similarly, so the key differentiator here is just which of the syntaxes you (and your team) find more legible.
Outside the box vs out-of-the-box
One final use-case that is admittedly not that common, but as a result also rarely spoken about, is cases where out-of-the-box methods are not fast enough or do not exist. In the following section, we are going to look at an illustrative example of a shift operation in Pandas vs NumPy.
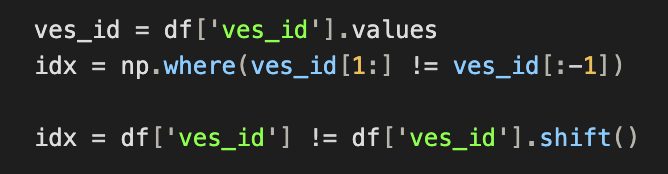
In this case, we wish to find occurrences where the `ves_id` field changes from one row to the next. The top 2 lines show a NumPy implementation of this, the 3rd line shows how this would be done using a Pandas `shift` operation. There is a similar NumPy method available, however, it behaves slightly differently than a Pandas shift, and is not appropriate for this use-case. We can see that the NumPy implementation is more verbose and less legible than a simple `shift` call. However, let us assume that we have a code-base littered with NumPy slicing calls because for whatever reason, our Pandas `shift` was not performant enough (this will almost never be the case, but just humour me for this example). What can we do to keep the performance of the NumPy slicing syntax, but make it more legible?
We must consider a dogma that virtually every programmer has come across:
“Code is going to be read more times than it is going to be written”
The answer is programming 101 – wrap it in a function. This may sound painfully obvious, but when you are deep into a data processing workflow, it can be easy to write your custom syntax once, and then one more time, and one more? and before you know it, it has spread like knotweed throughout your code.

Here, we have simply replaced our list slicing syntax with a function named `array_shift`. The very first benefit which stands out is that the function name is descriptive, and at the very least gives an idea as to what is going on. Looking at the function definition, we see another core benefit – docstrings!
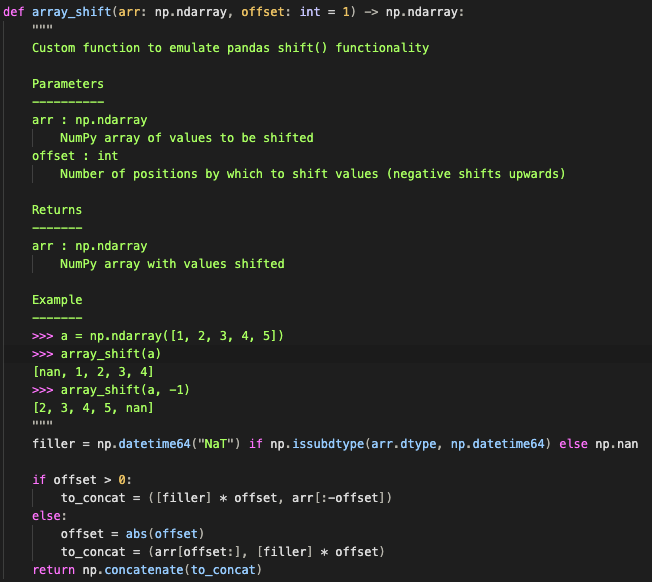
Although it is a custom function, we can give users and reviewers plenty of insight as to what is going on, and how it works, including some simple examples. The final benefit is that functions allow us to write comprehensive unit tests. Our array_shift function is testable, so we can ensure that it works as intended every time. Furthermore, using a shared function throughout your codebase, in place of repeated raw syntax, means that any bugs or issues you may discover in your custom approach can be fixed in one place and immediately distributed across every call in your codebase.
Conclusion
NumPy and Pandas are powerful tools for writing quick and effective data processing workflows. However, it is easy to get it wrong and incur significant performance penalties by using the wrong approaches. So here are some simple tips to bear in mind while creating your workflows.
- Vectorize wherever possible – it will be faster, and in most cases, it will be more legible too.
- If you must loop, use apply, but not all apply(s) are created equal, so ensure that you are apply(ing) correctly.
- “Premature optimization is the root of all evil” – the famous quote by Donald Knuth rings true here as it does elsewhere in programming. The techniques discussed here are powerful, but fast code is pointless if it generates the wrong output. Start by writing your Pandas code at whichever level you are comfortable with. Make absolutely sure that your logic is sound and that your code behaves as expected. Then, and only then, should you go back and look for common patterns which can be improved upon, ensuring that your optimised code returns exactly what it should.




