Arming commodity experts with Vortexa’s Python SDK
A quick guide for Analysts, Data Scientists and Engineers to get the most out of Vortexa’s Python SDK.
Wednesday, 22 January, 2020
Data Scientists care about data science, not engineering. Analysts need clear information at their fingertips, without hassle. Good engineers care deeply about the longevity of the systems they build, and waste no time with unnecessary low-level details.
Who should read this?
- Analysts starting to code
- Data Scientists that would prefer to focus on science
- 10x Engineers that expect effective abstractions
Modern data science requires both surgical precision and broad stroke data collection. Algorithms often need vast amounts of data to function effectively, while algorithm builders need pinpoint control to inspect the finer details.
It’s no small feat to navigate through millions of global waterborne oil movements. It requires a keen eye and a fair degree of patience to explore live ship-to-ship transfers, terminal-level cargo imports, and historic national export figures.
As discussed earlier, there are multiple ways to access our data. Here we will focus on Vortexa’s Python SDK.

We built the Vortexa Python Software Development Kit (SDK) to provide fast, interactive, programmatic exploration of our data.
The Python SDK empowers users to efficiently explore the world’s waterborne oil movements, and to build custom models & reports with minimum setup cost.
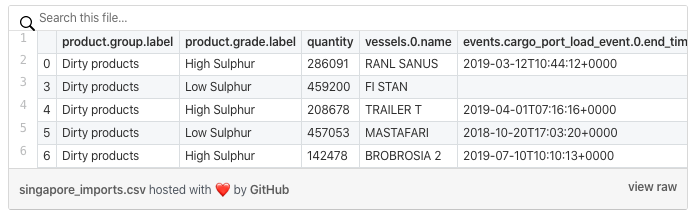
For example, to inspect cargo movements in a pandas DataFrame, we can run the following python snippet:
>>> df = CargoMovements()
.search(filter_activity='unloading_state',
filter_destinations=singapore,
filter_products=fuel_oil,
filter_time_min=datetime(2019, 1, 1),
filter_time_max=datetime(2019, 12, 31))
.to_df()
Returns the following:
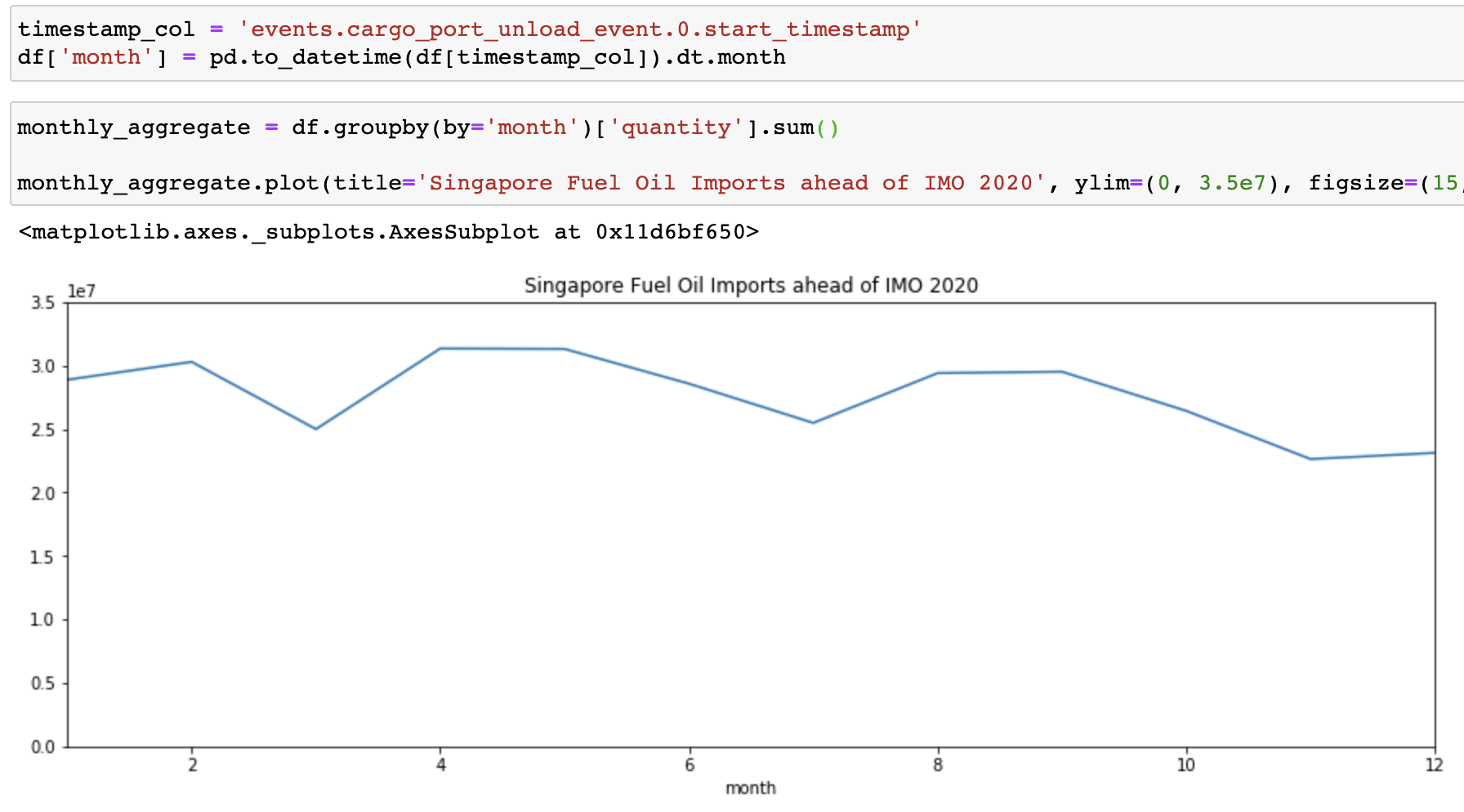
Let’s look deeper into this dataset, a quick monthly aggregate shows how Singapore’s Fuel Oil Imports are falling ahead of IMO 2020.
What should you expect from the Python SDK?
- Analysts can examine the world’s waterborne oil movements with minimum coding knowledge. Clear examples lead users along a gradual learning curve.
- Data Scientists can use an interactive python toolkit, deeply integrated with pandas. Data Scientists can use the SDK to efficiently combine multiple data sources, and methodically extract features relevant to both production & prototype models.
- Software & Data Engineers can rely on a modular, clean, test-driven, open-source SDK, built & maintained by a committed team of world-class engineers. We welcome contributions, please check out our contributing guide!
As a Data Scientist myself, it’s an interesting time to be in the industry. Data Scientists are becoming increasingly redundant, yet increasingly powerful at the same time. Advances in AutoML and tools like Ludwig allow you to build production-grade machine learning models in only a few lines of code.
Such powerful tooling lets us focus on understanding the data itself, doing away with details concerning hyper-parameter optimisation or type detection.
The SDK also aligns with this tool-driven mindset. At Vortexa, we’ve found it invaluable to build powerful tooling that simplifies the process of handling data. We hope you find the SDK similarly valuable.
Author: Kit Burgess, Data Scientist at Vortexa
For more practical tips on Data Science and Tech – follow the VorTECHsa team on Medium




