Using Rust in-process with Java
How scaling vertically can make horizontal scaling achievable. Integrating the Java JVM and Rust, and how it impacts Vortexa’s ability to compete. Performance isn’t just about software running efficiently.
Image: Patrick Tomasso
How scaling vertically can make horizontal scaling achievable.
This is another of my blog posts about performance, integrating the Java JVM and Rust, and how it impacts Vortexa’s ability to compete. Performance isn’t just about software running efficiently, as will become clear.
The problem domain
At Vortexa we track energy flows, and one of the things we need to do is predict where ships are going next.
They tell us. Sometimes. The signals can be wrong, missing, badly set, or stale. If you pardon the pun, a sea of human error.
Because of this we use an algorithm to process the data and make predictions. One of the many features input into this model is the feasibility of a prediction e.g. the model says a vessel may be heading towards port X – is this physically possible?
Now we can’t just measure “as the crow flies” or “great circle” distances, we need to know if a vessel is taking an appropriate route taking into account land masses in the way, and we need to be able to estimate when it might arrive. Thus we have an algorithm coupled with a geographical path-finding web-service.
We do this in response to live signals. However there comes a point where you want to measure what your system predicted in the past, to see if it was actually correct. You want to be able to test your models and algorithms, tweak them, iterate. Here we hit a major performance problem.
Business as usual
Within AWS, our incoming AIS signals from vessels are put into a Kafka stream which our model consumes, and predictions are placed on another Kafka stream.
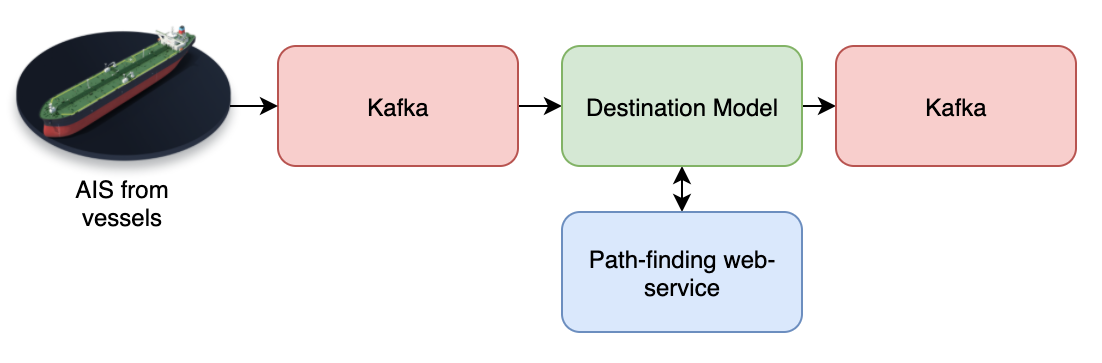
During calculations, calls are made to the path-finding web-service, via an auto-scaling load-balancer. If we get a burst of incoming data, we can automatically scale-up the web-service to match demand. When the demand is weak, we can scale down and not waste resources. Both the model and web-service instances run in Kubernetes.
This setup works just fine. The problems start when we want to analyse past predictions, and experimentally run the model against large amounts of historical data, when we want to experiment and iterate.
What is a web-service anyway?
At an application level, the path-finding service listens to HTTP requests, takes some input parameters and returns a JSON result.
What about at a lower level?
All web-services listen to a TCP socket, and incoming requests (to make TCP connections, to start the HTTP protocol) are placed on a finite-sized queue.
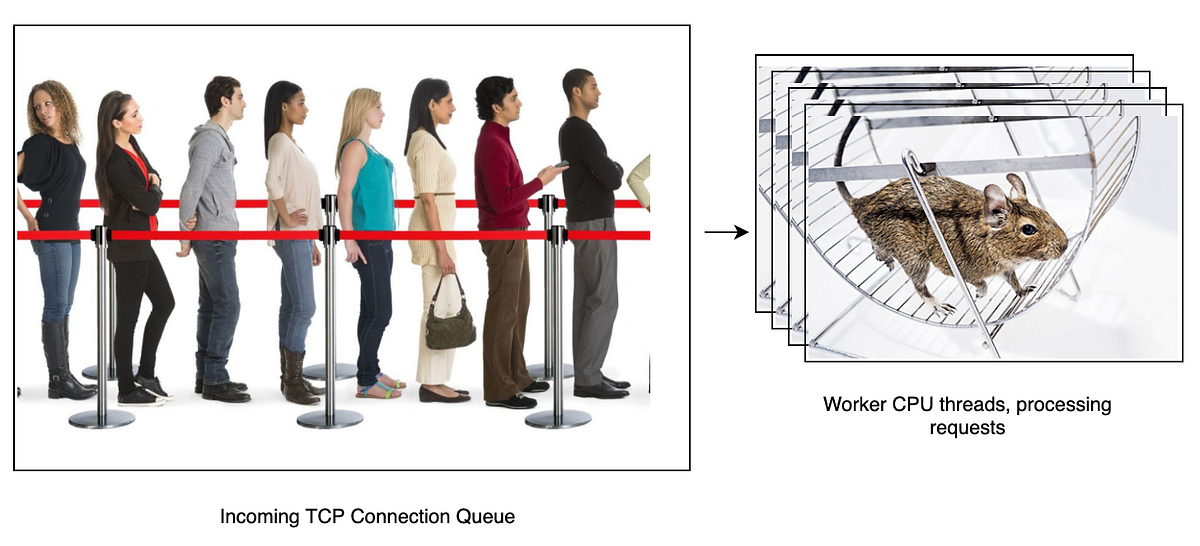
You then have one or more CPU threads reading requests from this queue, opening the TCP connections and serving the HTTP requests.
The problem is the queue is of finite length. If that queue gets full, incoming requests are rejected. This means we now have an application-level error – in our case this means the model client needs to handle retrying requests with some random backoff period. This in turn stalls that thread of execution and hits efficiency hard.
What about the load-balancer?
The load-balancer doesn’t have visibility on the queue length. It can see and react to CPU load. However, it takes time to provision a new pod in Kubernetes, and it takes time to start a new instance of the web-service as it loads a complex model.
When running against historical vessel data, demand peaks very quickly, the load-balancer cannot react quickly enough and we immediately get in a situation where many requests need retries. Effectively, we’re amplifying the problem by magnifying the load.
Our back-pressure mechanism is very weak – this is the crucial problem.
What about relying on HTTP/2?
We considered it, but although strictly speaking the specification doesn’t require it, TLS encryption is effectively required everywhere to make this work, which has its own overhead. That and distributing certificates and re-working some code, it felt too much like modifying infrastructure to suit application needs.
We also considered RSocket and gRPC, other means to get reliable back-pressure between client and server in place. The application development cost would be non-trivial, and it’d be a real pain for the infrastructure team to maintain something “special” for one use-case.
Speaking of costs?
To get this whole system to work with a large amount of historical data, we needed to split the task up in a simple map-reduce manner. We have ten tasks working on 1/10th of the data in parallel, plus a simple task to aggregate the results together afterwards.
Here’s an example of an experiment we ran.
Each model needed 3 CPU cores and 64GB of memory. We couldn’t effectively use more cores due to the web-service overloading/retry issues. These model instances were hooked up via a load-balancer to the path-finding web-services, which use little memory but 6 CPU cores each. We capped the path-finding scaling at 12 instances.
The processing took about 6 days to complete.
If anything went awry with the experiment, or if a developer decided it needed to be re-run with modified parameters, another 6 days would pass. The AWS compute costs alone would be over $1100 per run.
This was clearly massively expensive in both compute costs, and the huge delay developers and data scientists faced when trying to iterate the models and improve them. It was effectively a cap on the complexity (and thus accuracy) of the model calculations.
In principle, we could try to scale horizontally. However, because of the fundamental flaws in the architecture with the queue overloading issues, it was found even doubling the resources perhaps increased the execution speed by 30%. Running experiments to try and get the right parameters was in itself a very expensive exercise. We were up against a scalability wall.
A reminder of all the problems here
- We can’t scale
- Very high execution cost (AWS costs)
- Very high execution cost (developers and data scientists being unable to iterate effectively)
- Human error risk (a bug in the code, bad configuration, AWS failure etc.) magnified
- Risk of not pushing out improvements to customers in a realistic timeframe
- Limit on our ability to compute, and thus enrich and improve the model
There are a number of lower-level issues causing the performance problems here, but the ineffective back-pressure between the client and web-service is the main culprit. Secondary to this is network and serialization overheads. Network technology is not invisible.
These issues do not increase linearly with horizontal scaling but are magnified.
Let’s go vertical!
Like our previous integration story of Rust and Python, let’s try bringing systems together again.
Our model is JVM-based, mainly Kotlin with some Java. The path-finding web-service is written in Rust and the compute side is already heavily optimised. What if the model could call the path-finding logic in-process?
We built a small wrapper around the Rust logic using the jni Rust crate.
Java Native Interface, or JNI, allows “native” code (i.e. compiled code such as C++, Rust etc.) to interact with Java in the same process. This means two languages working in tandem within the same program (process) – it is not two programs (processes) communicating with each other.
Our wrapper exposes the path-finding Rust logic as a Java method call, taking normal Java arguments, and returning real Java data-structures in return. The Rust logic does not make use of secondary threads, but it is re-entrant, so it can be called in parallel by many threads at once.
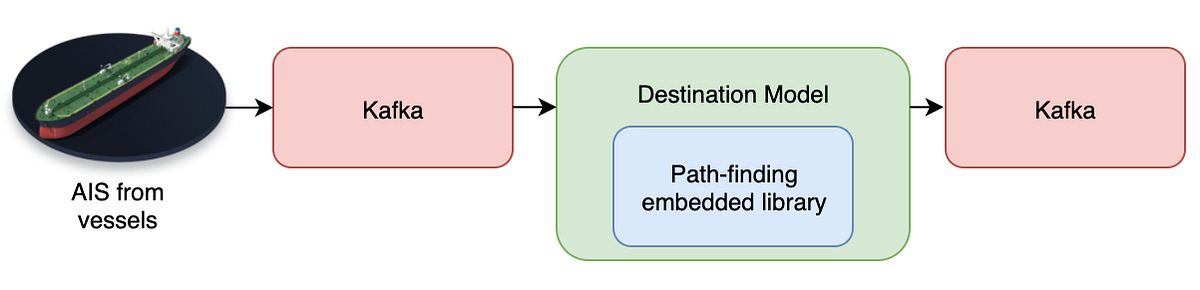
Advantages:
- The interface between the model and path-finding is now 100% reliable, no retries and no retry-logic required
- We had both a Java result cache and a cache implemented within the Rust web-service, as this is all happening now in one process we can drop the former and be more memory efficient
- No JSON serialization and deserialization overheads, no network overheads, the service (now an in-process library) returns real Java data structures directly
- As we have no retries, no waiting, we can effectively use many threads, which also means we can effectively make better use of that 64GB of model memory, reducing costs (more compute per GB of RAM used).
We decided to use 32 threads for model processing, which hand-off to another 32 threads for path-finding processing. All this on a 32-core AWS instance.
Yes, this does mean we’ll be context switching a little but that overhead is trivial compared with the other effects being described here. The balance between model load and path-finding load is very dynamic, so the best approach is to saturate the machine. If we’re using 100% of the CPU, it essentially doesn’t matter the ratio of compute between the two thread pools, work is getting done and we’re completely leveraging the resources we’re paying for. We can’t ask for more.
The Results
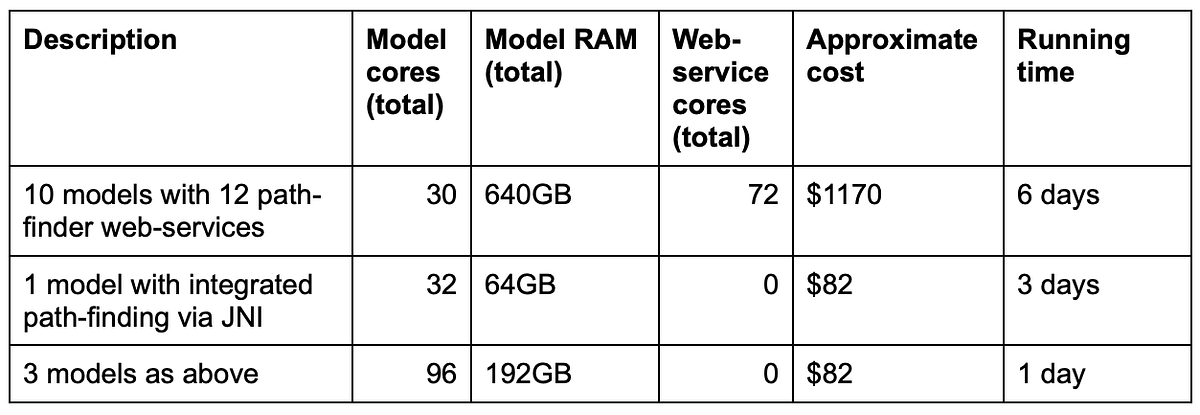
What we have achieved here:
- ~15x reduction in compute costs
- By vertically scaling the model architecture, we have achieved horizontal scalability
- We can now more aggressively demand computations within our models, improving the quality of their output
- Within reason, we can dial this up further to get results within hours for essentially the same low-cost
Our volume control now goes up to 11?

On Packaging
Another goal when making this change was not to tie two codebases closely together. The model was accessing the path-finding web-service via a RESTful API, and we certainly didn’t want to wreck that decoupling by pouring all the code into one source-control repository.
Our path-finding repository now has CI which deploys a Maven artefact which includes the JNI wrapper and the path-finding Rust library. This can then be pulled into projects which need it as a standard Maven dependency.
The API “surface area” between the projects is minimised.
Conclusions
Java and Rust can work very well together, and this integration was achieved with minimal engineering effort. Web-services are not the only valid approach.
We didn’t have to adjust our infrastructure and do a whole bunch of complex testing.
The AWS cost of running experiments has been massively lowered.
We can now demand more complex calculations and thus improve the output data quality.
Our model engineers and data scientists can now iterate effectively and bring improvements to our customers at full speed.
At Vortexa we address exciting challenges in innovative ways, day-in, day-out. Sounds like you? We’re hiring.




